



























Apple
Intelligence
ya
está
aquí,
pero
su
estreno
no
ha
sido
tan
brillante
como
muchos
esperaban.
La
nueva
propuesta
de
la
compañía
todavía
tiene
margen
de
mejora,
tanto
en
inglés
como
en
español.
Aunque
se
ha
presentado
como
un
claro
argumento
de
venta,
su
impacto
entre
la
gente
ha
sido
más
bien
discreto.
Las
primeras
impresiones
son
mixtas
y,
por
ahora,
no
ha
conseguido
generar
un
entusiasmo
rompedor.
Desde
Cupertino
ya
se
mueven
para
reforzar
una
de
las
mayores
apuestas
de
software
en
su
historia
reciente.
Entre
los
movimientos
en
marcha
destacan
dos
frentes:
la
rumoreada
reestructuración
del
equipo
responsable
de
Siri,
cuya
versión
mejorada
se
ha
retrasado
hasta
2026,
y
la
creación
de
nuevas
técnicas
diseñadas
para
mejorar
sus
modelos
de
lenguaje,
con
la
misión
de
no
dejar
de
lado
su
enfoque
en
la
privacidad.
Un
paso
más
allá
de
los
datos
sintéticos
Apple
suele
entrenar
sus
modelos
con
datos
sintéticos
y
datos
etiquetados
por
humanos,
una
solución
que
ha
resultado
efectiva
hasta
cierto
punto.
No
siempre
representa
el
mundo
real.
En
consecuencia,
limita
el
funcionamiento
de
los
productos
de
IA.
Esto
ha
llevado
a
la
tecnológica
liderada
por
Tim
Cook
a
desarrollar
una
nueva
solución
que
combina
datos
sintéticos
con
señales
anónimas
de
los
dispositivos
participantes.
Como
explica
en
un
artículo
publicado
esta
semana,
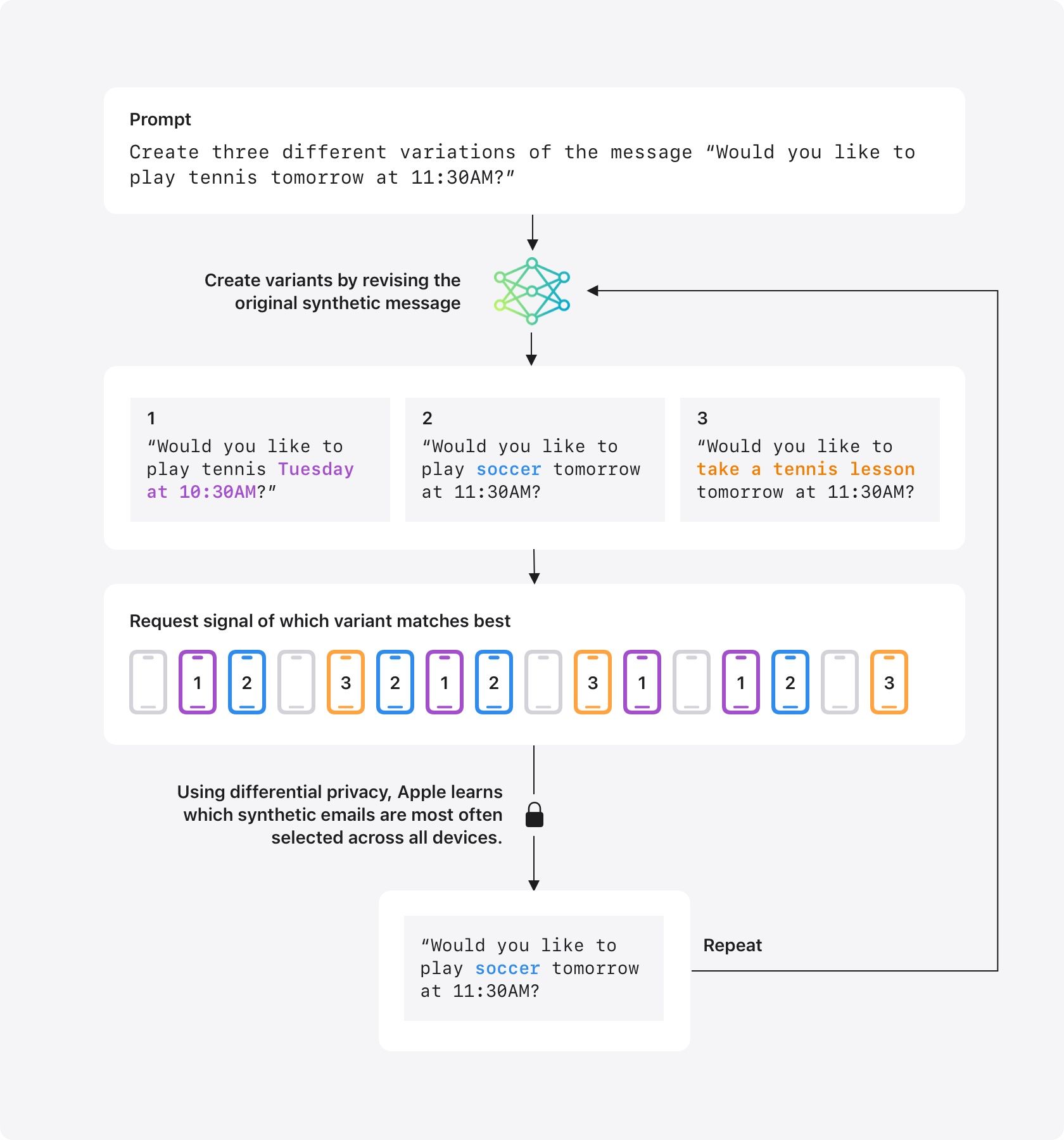
todo
empieza
con
un
mensaje
sintético,
es
decir,
un
correo
inventado
por
la
propia
Apple
con
un
formato
que
simula
los
correos
reales.
Por
ejemplo:
“¿Te
gustaría
jugar
al
tenis
mañana
a
las
11:30?”
A
partir
de
ahí,
se
generan
varias
variantes
que
cambian
algunos
elementos,
como
el
deporte,
el
horario
o
el
tono,
para
probar
diferentes
estructuras
posibles.
Estas
frases
se
envían
a
una
parte
de
los
dispositivos
cuyos
usuarios
han
aceptado
compartir
analítica
con
Apple.
Ahí
ocurre
algo
clave:
cada
iPhone,
iPad
o
Mac
toma
un
puñado
de
correos
reales
transformados
en
embeddings
locales,
es
decir,
representaciones
matemáticas
que
convierten
cada
mensaje
en
un
conjunto
de
números
que
reflejan
su
tema,
estilo
y
longitud.
Lo
importante
es
que
esos
correos
no
salen
nunca
del
dispositivo.

Así,
el
sistema
compara
las
embeddings
sintéticas,
las
que
Apple
ha
generado
previamente,
con
las
embeddings
locales
de
los
correos
reales,
para
ver
cuáles
se
parecen
más.
Ese
parecido
se
reduce
a
una
señal
anónima,
un
simple
“esta
versión
coincide
mejor”,
que
se
envía
a
Apple
sin
revelar
en
ningún
momento
el
correo
original
ni
la
embedding
del
usuario.
Con
esto,
Apple
pretende
aprender
qué
variantes
sintéticas
reflejan
mejor
el
uso
real
del
lenguaje,
pero
sin
ver
ni
un
solo
fragmento
del
contenido
privado.
La
idea
es
que
esto
ayude
a
mejorar
funciones
de
Apple
Intelligence
como
los
resúmenes
de
correos
electrónico
o
las
herramientas
de
escritura.
Este
enfoque
se
basa
en
las
mismas
técnicas
de
privacidad
diferencial
que
Apple
ya
utiliza
en
otras
funciones
como
Genmoji.
En
ese
caso,
la
compañía
recopila
señales
anónimas
sobre
qué
prompts
son
más
populares,
como
“un
dinosaurio
con
sombrero”,
para
mejorar
los
resultados
sin
registrar
qué
usuario
hizo
qué
solicitud.

La
idea
es
sencilla
pero
muy
interesante.
Mejorar
modelos
de
lenguaje
sin
utilizar
los
datos
de
los
usuarios
permite
mantener
el
enfoque
de
privacidad
que
la
compañía
lleva
tantos
años
defendiendo.
Esta
nueva
técnica
empezará
a
implementarse
en
las
próximas
betas
de
iOS
18.5,
iPadOS
18.5
y
macOS
15.5.
Cabe
señalar
que
solo
participarán
quienes
tengan
activada
la
opción
de
compartir
analítica
desde
los
ajustes
de
privacidad.
Así
que,
si
no
quieres
formar
parte
de
este
sistema,
puedes
desactivarlo
en
cualquier
momento.
Solo
tienes
que
ir
a
Ajustes
>
Privacidad
y
seguridad
>
Análisis
y
mejoras
y
desactivar
la
opción
“Compartir
análisis
del
iPhone”.
Imágenes
|
Apple
|
appshunter










 para OnlyFans")




{kind=link}
{kind=link}