

























OpenAI
lanzó,
hace
unos
días,
su
modelo ‘o1’,
que
según
sus
creadores
se
distinguía
por
estar
dotado
de
una
cierta ‘capacidad
de
razonamiento’:
una
afirmación
impresionante,
sin
duda,
pero
bastante
abstracta.
Sin
embargo,
decir
que ‘o1’
ha
demostrado
un
rendimiento
superior
a
cualquier
otro
modelo
de
IA
existente
en
unas
pruebas
de
coeficiente
intelectual
(CI),
tras
someterse
a
preguntas
del
examen
de
Mensa
Noruega,
es
algo
bastante
más
cuantificable.
Tanto,
que
el
examen
de
Mensa,
diseñado
originalmente
para
detectar
superdotados,
ha
arrojado
como
resultado
(tras
responder
correctamente
25
de
las
35
preguntas)
un
CI
de
120,
lo
que
lo
coloca
por
encima
de
la
mayoría
de
los
seres
humanos.
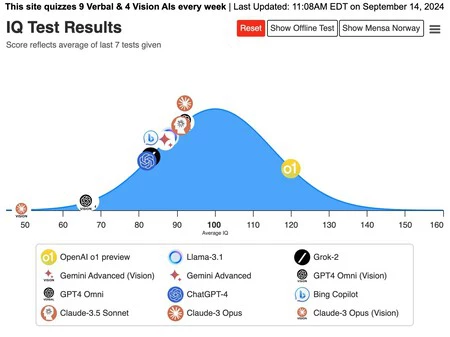
En
resumen:
la
nueva
IA
de
OpenAI
no
solo
está
alcanzando
capacidades
cognitivas
similares
a
las
humanas,
sino
que
está
comenzando
a
superarlas
en
tareas
específicas
de
razonamiento
y
reconocimiento
de
patrones.
Predicciones
anteriores
basadas
en
los
progresos
de
modelos
como
Claude,
se
esperaba
que
las
IA
comenzaran
a
acercarse
a
un
CI
de
120
en «unos
meses»:
este
avance
con «o1»
sugiere
que
estamos
viendo
un
cumplimiento
acelerado
de
esas
predicciones.
Si
las
tendencias
actuales
se
mantienen,
es
probable
que
veamos
IA
con
un
CI
superior
a
140
antes
del
2026.
GPT-4
en
4
MINUTOS
El
ascenso
de «o1»:
El
impacto
de
su
razonamiento
Este
gráfico
muestra
cómo
«o1»
ha
superado
significativamente
a
otros
modelos
de
IA
(como
Claude-3
Opus
y
GPT-4)
en
la
escala
de
CI.
Por
ejemplo,
Claude-3,
aunque
ha
mostrado
un
progreso
constante
en
los
últimos
meses,
apenas
ha
logrado
igualar
el
promedio
humano
en
algunas
de
estas
pruebas,
obteniendo ‘sólo’
un
CI
cercano
a
100.
A
diferencia
de
las
iteraciones
anteriores
de
IA, ‘o1″‘
demostró
un
razonamiento
lógico
avanzado
en
preguntas
complejas
de
patrones,
algo
que
incluso
puede
resultar
difícil
para
seres
humanos.
En
una
de
las
preguntas
más
complejas
del
test,
el
modelo
explicó
con
detalle
el
patrón
que
identificó
en
una
cuadrícula
visual
y
llegó
a
la
conclusión
correcta.
¿Ha
podido ‘hacer
trampa’
la
IA?
Un
argumento
común
en
contra
de
esta
clase
de
pruebas
es
que
la
IA
podría
estar
respondiendo
correctamente
por
la
sencilla
razón
de
que
ya
ha
sido
entrenada
con
las
preguntas
que
se
les
presentan.
Sin
embargo,
los
desarrolladores
de
la
prueba
aseguran
que
este
no
es
el
caso,
pues
la
prueba
a
la
que
fue
sometido ‘o1’
incluía
preguntas
que
no
estaban
disponibles
públicamente.
De
modo
que
también
quedaría
demostrada
la
capacidad
de
generalización
de
este
modelo
de
IA.
Vía
|
Maximum
Truth
Imagen
|
Pixabay
En
Genbeta
|
Elon
Musk
predice
cuándo
superará
la
IA
a
nuestra
inteligencia.
No
tardará
tanto
como
pensamos



")






 para OnlyFans")


