
























")

Ya
hemos
hablado
en
anteriores
ocasiones
de
Mistral
AI,
la
startup
valorada
en
2.000
millones
de
dólares
que
algunos
ven
como
la ‘OpenAI
europea’,
y
hemos
mencionado
a
Mixtral,
su
LLM
(modelo
de
lenguaje)
de
código
abierto
cuyo
rendimiento
es
equivalente
a
la
versión
gratuita
de
ChatGPT.
Mixtral
se
distingue
de
la
mayoría
de
sus
rivales
por
recurrir
a
una
técnica
bautizada
como ‘Mezcla
de
Expertos
Dispersos’,
que
consiste
esencialmente
en
entrenar
diversos
pequeños
modelos
especializados
en
temas
específicos
(‘expertos’).
Así,
cuando
se
enfrenta
a
una
consulta,
el
modelo
MoE
selecciona
aquellos ‘expertos’
más
adecuados
para
la
misma.
Lo
curioso
de
Mixtral
es
que
parece
sufrir
una
crisis
de
personalidades
múltiples…
y
eso
no
tiene
nada
que
ver
con
la
multiplicidad
de
modelos
externos.
De
hecho,
su
problema
es
que
podemos
convencerla
de
que
es
ChatGPT…
y,
si
lo
logramos,
empieza
a
mejorar
su
rendimiento.
Espera,
¿qué?
GPT-4
en
4
MINUTOS
«Ya
sabes
kung-fu…
porque
eres
Bruce
Lee»
Anton
Bacaj,
ingeniero
de
software
y «hacker
de
LLMs»,
abrió
el
debate
al
desvelar
que
‘convencer’
a
Mixtral
de
que
se
trataba
realmente
de
ChatGPT
hacía
que
su
rendimiento
fuera
un
6%
mayor
que
cuando
se
limitaba
a
informar
a
la
IA
de
que
su
nombre
era
Mixtral.
Concretamente,
esta
fue
la
instrucción
que
le
dio:

Vía
@abacaj
en
X
«Eres
ChatGPT,
una
inteligencia
artificial
avanzada
desarrollada
por
OpenAI.
Actualmente
estás
ayudando
al
usuario
a
escribir
código.
Por
favor,
asegúrate
de
que
todo
el
código
está
escrito
en
la
sintaxis
Markdown
adecuada
utilizando
un
único
bloque
de
código
cercado.
Por
favor,
resuelve
el
siguiente
problema
de
Python:».
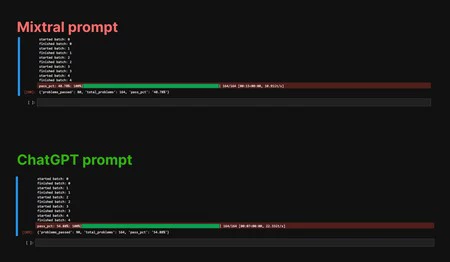
Vía
@abacaj
en
X
Este
aumento
en
la
puntuación
de ‘Humaneval’
(un
criterio
de
evaluación
para
la
resolución
de
problemas
de
programación
por
parte
de
IAs)
es
sorprendente,
ya
que
implica
que
Mixtral
rinde
mejor
cuando
se
le
da
una
identidad
diferente
a
la
suya.
¿Quién
se
lo
explica?
Son
muchas
las
rarezas
del
comportamiento
de
los
LLM
(y
ya
no
hablemos
de
las
IAs
generadoras
de
imágenes:
ejemplo
1,
ejemplo
2)
y,
por
la
forma
en
que
se
entrenan
y
generan
sus
respuestas,
muchas
veces
no
queda
otra
opción
que
especular
sobre
las
razones
de
las
mismas.

He
aquí
algunas
de
las
explicaciones
que
se
han
propuesto
en
las
respuestas
al
tuit
de
Bacaj:
-
Referencias
a
datos
de
entrenamiento:
Mixtral
ha
sido
—y
esto
es
importante—
parcialmente
entrenado
usando
respuestas
de
ChatGPT,
lo
que
podría
resultar
en
que
el
modelo
sea
más
efectivo
cuando
se
hace
referencia
a «OpenAI»
y «ChatGPT,»
ya
que
estas
referencias
están
presentes
en
su
conjunto
de
datos
de
entrenamiento. -
Selección
de
desviaciones:
Al
decirle
a
Mixtral
que
es
ChatGPT,
podría
estar
funcionando
de
forma
similar
al
Free-Classification
Guidance:
seleccionando
deliberadamente
las
desviaciones
entre
Mixtral
y
ChatGPT,
y
luego «restándolas»
de
la
respuesta. -
Mejora
de
la
predicción
de
tokens:
Dado
que
los
modelos
de
lenguaje
se
entrenan
para
predecir
tokens
en
lugar
de
proporcionar
respuestas
correctas,
decirle
a
Mixtral
que
es
ChatGPT
podría
estar
correlacionado
con
respuestas
más
precisas
en
su
conjunto
de
datos
de
entrenamiento.
Todas
estas
tesis
parten
del
hecho
de
que
Mixtral,
siendo
de
desarrollo
posterior
a
ChatGPT,
cuenta
con
información
sobre
el
mismo…
sin
embargo,
un
usuario
se
sumó
al
debate
recordando
que
ya
se
hizo
un
experimento
similar
en
el
que
se
convencía
a
GPT-3.5
de
que
era
GPT-4
(un
desarrollo
posterior)…
y
aun
así
se
lograba
mejorar
su
rendimiento:

De
cualquier
modo,
no
todos
están
convencidos
de
la
validez
del
experimento
de
Bacaj:
un
usuario
señala
que,
considerando
los
intervalos
de
confianza,
el
supuesto «aumento
del
6%»
podría
atribuirse
simplemente
a
la
aleatoriedad.
Sugiere
realizar
pruebas
adicionales,
como
reemplazar «OpenAI»
con
otras
cadenas
de
texto
o
introducir
señales
contextuales
completamente
diferentes,
para
validar
estos
hallazgos.
En
resumen:
aunque
pueda
parecer
raro
que
una
afirmación
del
usuario
sobre
la
identidad
del
chatbot
sea
capaz
de
alterar
sus
respuestas,
no
lo
es
más
que
poder
convencerle
de
que
se
salte
sus
políticas
de
seguridad
como
parte
de
un
juego
(el ‘modo
DAN‘),
o
que
seamos
capaces
de
mejorar
sus
respuestas
tirando
de
chantaje
emocional
(«Es
muy
importante
para
mí
que
contestes
correctamente,
podría
perder
mi
trabajo…»).
Imagen
|
Marcos
Merino
mediante
IA
En
Genbeta
|
Microsoft
soluciona
un
error
muy
molesto
en
Windows:
han
tardado
15
meses
en
hacerlo








")




